Los procesadores Itanium fueron desarrollados por Intel y HP entre los años 1989 y 2000. El lanzamiento se produjo finalmente en el año 2001 y en 2002 se lanzó al mercado Itanium 2 que corregía la jerarquía de memoria del primer diseño, que se mostró ineficiente, además de añadir más unidades funcionales. Esta versión ha tenido revisiones en las que se ha mejorado el proceso de fabricación, aumentado el tamaño de la memoria caché, añadido núcleos y algunas características como soporte para virtualización o multithreading.
El objetivo del diseño del itanium era conseguir una arquitectura que maximice el número de instrucciones por ciclo. A esta arquitectura se le conoce con el nombre EPIC (Explicitly Parallel Instruction Computing). La base de este diseño es utilizar instrucciones muy largas (128 bits) que en realidad contienen 3 instrucciones de 41 bits que pueden ejecutarse simultáneamente. Esta agrupación la realiza el compilador, que es el que tiene toda la responsabilidad en lugar de la lógica del procesador como sucede en los procesadores x86 más comunes, que pueden ejecutar fuera de orden.
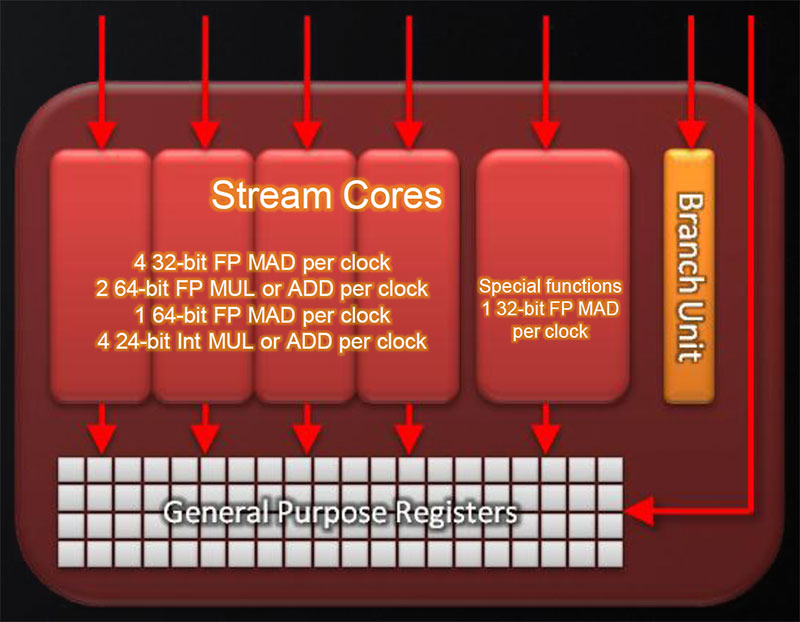
Este es un esquema de bloques del procesador Itanium original:
 Como hemos dicho, el objetivo del diseño es ejecutar el mayor número posible de instrucciones en paralelo. Por ello tiene un gran número de unidades funcionales en 11 grupos diferentes:
Como hemos dicho, el objetivo del diseño es ejecutar el mayor número posible de instrucciones en paralelo. Por ello tiene un gran número de unidades funcionales en 11 grupos diferentes:
El objetivo del diseño del itanium era conseguir una arquitectura que maximice el número de instrucciones por ciclo. A esta arquitectura se le conoce con el nombre EPIC (Explicitly Parallel Instruction Computing). La base de este diseño es utilizar instrucciones muy largas (128 bits) que en realidad contienen 3 instrucciones de 41 bits que pueden ejecutarse simultáneamente. Esta agrupación la realiza el compilador, que es el que tiene toda la responsabilidad en lugar de la lógica del procesador como sucede en los procesadores x86 más comunes, que pueden ejecutar fuera de orden.
Este es un esquema de bloques del procesador Itanium original:
 Como hemos dicho, el objetivo del diseño es ejecutar el mayor número posible de instrucciones en paralelo. Por ello tiene un gran número de unidades funcionales en 11 grupos diferentes:
Como hemos dicho, el objetivo del diseño es ejecutar el mayor número posible de instrucciones en paralelo. Por ello tiene un gran número de unidades funcionales en 11 grupos diferentes:- 6 ALUs de propósito general
- 2 unidades de enteros
- 1 unidad de desplazamiento de bits
- 4 unidades de acceso a caché
- 6 unidades de cálculo multimedia
- 2 unidades de desplazamiento de bits en paralelo
- 1 unidad de multiplicación en paralelo
- 1 unidad de "population count" (número de bits a 1 en un registro)
- 2 unidades de coma flotante de 82 bits
- 2 unidades de coma flotante SIMD
- 3 unidades de cómputo de saltos
Cada grupo de unidades puede ejecutar un subconjunto de instrucciones, dependiendo del tipo que sean. Las instrucciones más comunes pueden ser ejecutadas por más de 1 tipo de unidades. Cada instrucción pertenece a uno de los siguientes tipos:
- A: números enteros (ALU)
- I: números enteros (no ALU)
- M: acceso a memoria
- F: Punto flotante
- B: Salto
- L+X: Tipo extendido, dependiendo del subtipo se ejecuta en distintas unidades.
Por ejemplo las instrucciones de tipo A pueden ejecutarse en las unidades de enteros, en las ALUs de propósito general y en las de cálculo multimedia.
El procesador tiene una gran cantidad de unidades disponibles y reparte el trabajo según el tipo de instrucción entre ellas, mediante estaciones de reserva siguiendo la estrategia del algoritmo de Tomasulo. Si nos fijamos, un conjunto de 3 instrucciones ocupa 41*3=123 bits. Los 5 bits que faltan hasta 128 bits indican al procesador que combinación de tipos de instrucciones hay. Por ejemplo, 00001 indica que la primera instrucción es de tipo M, mientras que la 2ª y 3ª son de tipo I. Además de una gran cantidad de unidades funcionales, también tiene una gran cantidad de registros. Hay 128 registros de proposito general de 64 bits, 128 registros de coma flotante de 82 bits y 64 registros de predicación de 1 bit.
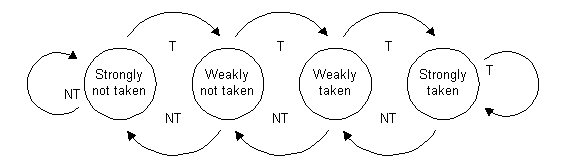
Para mantener las unidades funcionales activas, el procesador implementa varias técnicas conocidas. En primer lugar, emite dos instrucciones por ciclo de reloj. Teniendo en cuenta que cada una es un paquete con 3 instrucciones, son 6 las instrucciones efectivas que puede llegar a emitir. Otra técnica de la que hace uso este procesador es la predicción de saltos. El procesador tiene 2 predictores, uno de ellos es un buffer de predicción de salto, mientras que el 2º es un predictor de 2 niveles. También implementa un predictor de dirección de retorno para las llamadas a funciones. Lo más distintivo de este procesador es que el compilador puede añadir sugerencias sobre los saltos, haciendo que el procesador lo evalúe de manera dinámica (utilizando los predictores) o de manera estática (haciendo caso a la recomendación del compilador).
El procesador también tiene la capacidad de especular y también implementa una técnica que no es común en los procesadores actuales, que es la predicación. Al usar esta técnica, el procesador ejecuta las 2 ramas de un salto y descarta la que no se toma una vez conocido el resultado de la instrucción de salto. Esta técnica encaja con la gran cantidad de registros y unidades funcionales del procesador. Esto es especialmente práctico en el caso de saltos condicionales que ejecutan pocas instrucciones. El compilador puede elegir qué debe realizar el procesador. Para ello, cada instrucción tiene 6 bits reservados para indicar que registro de predicación indica si la instrucción se debe ejecutar o no. Hay un registro cuyo valor es siempre verdadero, por lo que se puede usar para ejecutar instrucciones sin predicción. El funcionamiento de esta técnica se puede ver en este esquema:
 En el caso de usar predicación, se evalúa que r1 valga 5 y el resultado se asigna a los registros de predicación qp1 y la negación a qp2. A continuación se ejecutan ambas ramas, solo que las operaciones cada una están asociadas un registro de predicación. El resultado de las ramas se utilizará o se desechará según el resultado final de la instrucción test. Otra vez más, es el compilador el que tiene la responsabilidad de utilizar la predicación adecuadamente.
En el caso de usar predicación, se evalúa que r1 valga 5 y el resultado se asigna a los registros de predicación qp1 y la negación a qp2. A continuación se ejecutan ambas ramas, solo que las operaciones cada una están asociadas un registro de predicación. El resultado de las ramas se utilizará o se desechará según el resultado final de la instrucción test. Otra vez más, es el compilador el que tiene la responsabilidad de utilizar la predicación adecuadamente.
La jerarquía de memoria está dividida en 3 niveles. La memoria de primer nivel está separada en 2, una para instrucciones y otra para datos. Ambas son asociativas por conjuntos (4) y tienen un tamaño de 16 KB cada una. La memoria de nivel 2 ha sufrido varios cambios. Inicialmente era una memoria asociativa por conjuntos (6) con un tamaño de 96 KB, compartida para código y datos. Con los procesadores Itanium II aumentaron el tamaño hasta 256 KB y la asociatividad a 8. Desde mediados del 2006 la memoria caché de nivel 2 está separada en una caché de datos de 256 KB y una de instrucciones de 1 MB. La memoria caché de nivel 3 se accedía a través del FSB en el caso de los primeros Itanium y consistía de una caché asociativa por conjuntos (2) de 2 ó 4 MB. Al revisar la jerarquía de memoria con los Itanium II se incluyó memoria caché asociativa por grupos (2 ó 4) de nivel 3 en el mismo integrado. El tamaño varía según el modelo desde 1.5 MB hasta 24 MB en los últimos modelos con 2 núcleos (12 por núcleo).

Este tipo de procesadores está orientado a la computación de alto rendimiento. La arquitectura Itanium consigue un rendimiento altísimo en cálculo en coma flotante y de hecho ha sido muy utilizada en supercomputadores.
Patxi Astiz
El procesador tiene una gran cantidad de unidades disponibles y reparte el trabajo según el tipo de instrucción entre ellas, mediante estaciones de reserva siguiendo la estrategia del algoritmo de Tomasulo. Si nos fijamos, un conjunto de 3 instrucciones ocupa 41*3=123 bits. Los 5 bits que faltan hasta 128 bits indican al procesador que combinación de tipos de instrucciones hay. Por ejemplo, 00001 indica que la primera instrucción es de tipo M, mientras que la 2ª y 3ª son de tipo I. Además de una gran cantidad de unidades funcionales, también tiene una gran cantidad de registros. Hay 128 registros de proposito general de 64 bits, 128 registros de coma flotante de 82 bits y 64 registros de predicación de 1 bit.
Para mantener las unidades funcionales activas, el procesador implementa varias técnicas conocidas. En primer lugar, emite dos instrucciones por ciclo de reloj. Teniendo en cuenta que cada una es un paquete con 3 instrucciones, son 6 las instrucciones efectivas que puede llegar a emitir. Otra técnica de la que hace uso este procesador es la predicción de saltos. El procesador tiene 2 predictores, uno de ellos es un buffer de predicción de salto, mientras que el 2º es un predictor de 2 niveles. También implementa un predictor de dirección de retorno para las llamadas a funciones. Lo más distintivo de este procesador es que el compilador puede añadir sugerencias sobre los saltos, haciendo que el procesador lo evalúe de manera dinámica (utilizando los predictores) o de manera estática (haciendo caso a la recomendación del compilador).
El procesador también tiene la capacidad de especular y también implementa una técnica que no es común en los procesadores actuales, que es la predicación. Al usar esta técnica, el procesador ejecuta las 2 ramas de un salto y descarta la que no se toma una vez conocido el resultado de la instrucción de salto. Esta técnica encaja con la gran cantidad de registros y unidades funcionales del procesador. Esto es especialmente práctico en el caso de saltos condicionales que ejecutan pocas instrucciones. El compilador puede elegir qué debe realizar el procesador. Para ello, cada instrucción tiene 6 bits reservados para indicar que registro de predicación indica si la instrucción se debe ejecutar o no. Hay un registro cuyo valor es siempre verdadero, por lo que se puede usar para ejecutar instrucciones sin predicción. El funcionamiento de esta técnica se puede ver en este esquema:
 En el caso de usar predicación, se evalúa que r1 valga 5 y el resultado se asigna a los registros de predicación qp1 y la negación a qp2. A continuación se ejecutan ambas ramas, solo que las operaciones cada una están asociadas un registro de predicación. El resultado de las ramas se utilizará o se desechará según el resultado final de la instrucción test. Otra vez más, es el compilador el que tiene la responsabilidad de utilizar la predicación adecuadamente.
En el caso de usar predicación, se evalúa que r1 valga 5 y el resultado se asigna a los registros de predicación qp1 y la negación a qp2. A continuación se ejecutan ambas ramas, solo que las operaciones cada una están asociadas un registro de predicación. El resultado de las ramas se utilizará o se desechará según el resultado final de la instrucción test. Otra vez más, es el compilador el que tiene la responsabilidad de utilizar la predicación adecuadamente.La jerarquía de memoria está dividida en 3 niveles. La memoria de primer nivel está separada en 2, una para instrucciones y otra para datos. Ambas son asociativas por conjuntos (4) y tienen un tamaño de 16 KB cada una. La memoria de nivel 2 ha sufrido varios cambios. Inicialmente era una memoria asociativa por conjuntos (6) con un tamaño de 96 KB, compartida para código y datos. Con los procesadores Itanium II aumentaron el tamaño hasta 256 KB y la asociatividad a 8. Desde mediados del 2006 la memoria caché de nivel 2 está separada en una caché de datos de 256 KB y una de instrucciones de 1 MB. La memoria caché de nivel 3 se accedía a través del FSB en el caso de los primeros Itanium y consistía de una caché asociativa por conjuntos (2) de 2 ó 4 MB. Al revisar la jerarquía de memoria con los Itanium II se incluyó memoria caché asociativa por grupos (2 ó 4) de nivel 3 en el mismo integrado. El tamaño varía según el modelo desde 1.5 MB hasta 24 MB en los últimos modelos con 2 núcleos (12 por núcleo).

Este tipo de procesadores está orientado a la computación de alto rendimiento. La arquitectura Itanium consigue un rendimiento altísimo en cálculo en coma flotante y de hecho ha sido muy utilizada en supercomputadores.
Patxi Astiz









.png)