En general las instrucciones de salto son muy habituales en el código y por lo tanto los riesgos asociados a estas también, por lo que la predicción de saltos es algo inévitable en cualquier procesador moderno. Recordemos brevemente los 2 tipos de predictores dinámicos más sencillos. Uno es el predictor de 1 bit, y simplemente predice que un salto hará lo mismo que hizo la vez anterior. El 2º es el predictor de 2 bits, cuya máquina de estados es la siguiente: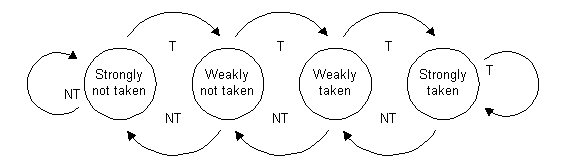 En este caso se tiene en cuenta lo que ha sucedido en los 2 últimos saltos. En el diagrama de estados, 'T' significa 'Taken', es decir que se salta y 'NT' significa 'Not Taken', es decir que no se toma el salto. Como puede verse, si un salto se ha tomado sistemáticamente, hace falta que no se salte 2 veces seguidas para cambiar la predicción. Este predictor permite evitar los fallos del predictor de 1 bit al salir y entrar en los bucles, pero todavía es susceptible de mejora.
En este caso se tiene en cuenta lo que ha sucedido en los 2 últimos saltos. En el diagrama de estados, 'T' significa 'Taken', es decir que se salta y 'NT' significa 'Not Taken', es decir que no se toma el salto. Como puede verse, si un salto se ha tomado sistemáticamente, hace falta que no se salte 2 veces seguidas para cambiar la predicción. Este predictor permite evitar los fallos del predictor de 1 bit al salir y entrar en los bucles, pero todavía es susceptible de mejora.
El predictor del que vamos a hablar es el predictor adaptativo de 2 niveles, originalmente propuesto por Tse-Yu Yeh y Yale N. Patt en 1991 en el paper "Two-Level Adaptative Training Branch Prediction". Hay variaciones sobre el esquema original que se utilizan en los procesadores modernos.
La idea original es dividir el predictor en 2 estructuras. Por una parte un historial de saltos y por otra una tabla con un historial de patrones. En la primera tabla, para cada instrucción de salto, se almacenan en registros de desplazamientos la información de si se tomó o no en las anteriores 'n' ejecuciones. Un '1' significa que sí mientras un '0' que no se saltó. Si por ejemplo un salto se toma 3 veces seguidas y a la 4ª no, el valor de su historial de saltos será '1110'. Este valor no se utiliza directamente para hacer la predicción, sino que sirve de índice para mirar en la 2ª tabla, la que contiene los patrones de comportamiento del salto. El valor que leemos de esta segunda tabla es en realidad el estado de una máquina de estados como puede ser el predictor de 1 bit o el de 2 bits que hemos visto anteriormente. Veamoslo con un esquema.
 Cómo se puede ver, básandose en el historial de saltos tenemos el índice con el que buscar en la tabla de patrones, que nos devolverá el estado con el cual haremos la predicción definitiva. Cuando el salto se resuelva definitivamente, podremos actualizar el estado correspondiente.
Cómo se puede ver, básandose en el historial de saltos tenemos el índice con el que buscar en la tabla de patrones, que nos devolverá el estado con el cual haremos la predicción definitiva. Cuando el salto se resuelva definitivamente, podremos actualizar el estado correspondiente.
Veamos un ejemplo, supongamos que tenemos un salto que siempre se toma 3 veces seguidas, la 4º no se toma y este patrón se repite indefinidamente. Tras unas cuantas ejecuciones de dicha instrucción, tendremos información almacenada en la tabla de patrones, para diferentes índices. Por ejemplo, para el índice '1011' el estado almacenado indicará que hay que tomar el salto, ya que en las anteriores veces siempre se ha saltado. Sin embargo para el índice '0111' el estado almacenado en la tabla debe indicar que no hay que tomar el salto.
Este diseño ha sido el origen de una familia de predictores que mantienen 2 estructuras (una con un historial de saltos y otra con el comportamiento), pero pueden diferenciarse en 3 aspectos:
En este caso se tiene en cuenta lo que ha sucedido en los 2 últimos saltos. En el diagrama de estados, 'T' significa 'Taken', es decir que se salta y 'NT' significa 'Not Taken', es decir que no se toma el salto. Como puede verse, si un salto se ha tomado sistemáticamente, hace falta que no se salte 2 veces seguidas para cambiar la predicción. Este predictor permite evitar los fallos del predictor de 1 bit al salir y entrar en los bucles, pero todavía es susceptible de mejora.El predictor del que vamos a hablar es el predictor adaptativo de 2 niveles, originalmente propuesto por Tse-Yu Yeh y Yale N. Patt en 1991 en el paper "Two-Level Adaptative Training Branch Prediction". Hay variaciones sobre el esquema original que se utilizan en los procesadores modernos.
La idea original es dividir el predictor en 2 estructuras. Por una parte un historial de saltos y por otra una tabla con un historial de patrones. En la primera tabla, para cada instrucción de salto, se almacenan en registros de desplazamientos la información de si se tomó o no en las anteriores 'n' ejecuciones. Un '1' significa que sí mientras un '0' que no se saltó. Si por ejemplo un salto se toma 3 veces seguidas y a la 4ª no, el valor de su historial de saltos será '1110'. Este valor no se utiliza directamente para hacer la predicción, sino que sirve de índice para mirar en la 2ª tabla, la que contiene los patrones de comportamiento del salto. El valor que leemos de esta segunda tabla es en realidad el estado de una máquina de estados como puede ser el predictor de 1 bit o el de 2 bits que hemos visto anteriormente. Veamoslo con un esquema.
 Cómo se puede ver, básandose en el historial de saltos tenemos el índice con el que buscar en la tabla de patrones, que nos devolverá el estado con el cual haremos la predicción definitiva. Cuando el salto se resuelva definitivamente, podremos actualizar el estado correspondiente.
Cómo se puede ver, básandose en el historial de saltos tenemos el índice con el que buscar en la tabla de patrones, que nos devolverá el estado con el cual haremos la predicción definitiva. Cuando el salto se resuelva definitivamente, podremos actualizar el estado correspondiente.Veamos un ejemplo, supongamos que tenemos un salto que siempre se toma 3 veces seguidas, la 4º no se toma y este patrón se repite indefinidamente. Tras unas cuantas ejecuciones de dicha instrucción, tendremos información almacenada en la tabla de patrones, para diferentes índices. Por ejemplo, para el índice '1011' el estado almacenado indicará que hay que tomar el salto, ya que en las anteriores veces siempre se ha saltado. Sin embargo para el índice '0111' el estado almacenado en la tabla debe indicar que no hay que tomar el salto.
Este diseño ha sido el origen de una familia de predictores que mantienen 2 estructuras (una con un historial de saltos y otra con el comportamiento), pero pueden diferenciarse en 3 aspectos:
- El historial de saltos se guarda por instrúcción (P), es global (G), en cuyo caso solo hay un registro o se guarda una entrada por cada N saltos (S).
- La tabla de patrones es de tipo dinámica o adaptativa (A) o estática (S).
- La tabla de patrones tiene entradas para cada instrucción de salto (p), para conjuntos de N saltos (s) o son globales (g).
Según estos 3 parámetros decimos que tenemos un predictor PAg en el caso del expuesto en el paper de Yeh y Patt, ya que el historial de saltos se almacena para cada instrucción de salto (P), la tabla de patrones guarda un estado dinámico (A) y es una tabla global (g), es decir no guarda valores diferentes para diferentes instrucciones de salto. Por ejemplo el predictor GAg es a veces conocido como gshare y lo utilizan los últimos procesadores tanto de AMD como de Intel.
Los procesasdores modernos hacen una predicción de saltos muy compleja ya que esto puede suponer una ventaja apreciable de rendimiento sobre sus competidores. En la actualidad es bastante común que los procesadores tengan predictores híbridos, es decir, mezclen la estimación de distintos tipos de predictores, como puede ser uno de 2 niveles GAg con uno de 2 bits. Además pueden incluir predictores especializados en detectar bucles o en predecir las direcciones de retorno de llamadas a funciones entre otros.
Patxi Astiz
Los procesasdores modernos hacen una predicción de saltos muy compleja ya que esto puede suponer una ventaja apreciable de rendimiento sobre sus competidores. En la actualidad es bastante común que los procesadores tengan predictores híbridos, es decir, mezclen la estimación de distintos tipos de predictores, como puede ser uno de 2 niveles GAg con uno de 2 bits. Además pueden incluir predictores especializados en detectar bucles o en predecir las direcciones de retorno de llamadas a funciones entre otros.
Patxi Astiz
.png)
