Como ya hemos visto, el procesador Cell tiene una arquitectura que exige un esfuerzo extra al programador a la hora de adecuar el programa a las peculiaridades del hardware. Esto es importante si se quiere aprovechar la capacidad del procesador y para ello hay varios modelos de programación que se pueden seguir.
En primer lugar se puede programar para Cell como si fuera un procesador de propósito general, al tener un núcleo PowerPC con VMX. Este modelo es muy sencillo pero obviamente desaprovecha la mayor parte de la potencia de cálculo del procesador. Sin embargo para tareas en las que esta potencia no es realmente necesaria compensa el menor tiempo y coste de desarrollo.
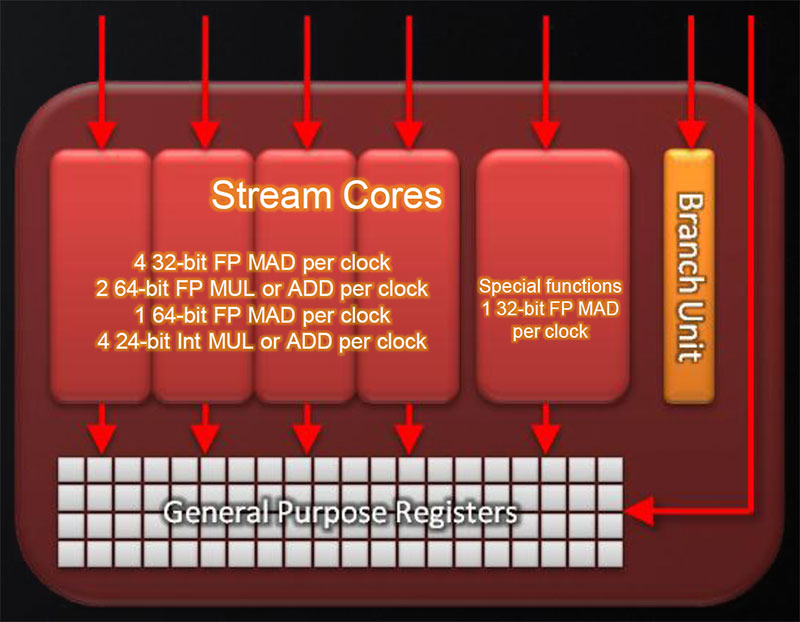
El siguiente paso en cuanto a complejidad consiste en utilizar un SPE para realizar ciertas tareas concretas. Mientras que el programa se ejecuta en el PPE, parte del algoritmo puede que se beneficie de la potencia de cálculo de los SPE. En ese caso se programa y compila para un SPE y desde el PPE se encarga de configurar el procesador para que se ejecute cuando haga falta. Este modelo de programación utiliza los SPEs como una ayuda en momentos puntuales. Esto introduce una dificultad añadida que es la gestión de la memoria. Cada SPE tiene una memoria local de 256 KB y puede acceder a la memoria principal mediante DMA. En caso de que los datos y el código no quepan en la memoria local hay que incluir código que gestione los datos de la memoria local y el acceso a memoria principal para que el SPE no se quede parado a la espera de los datos que necesite.
Para aprovechar al máximo los recursos que nos ofrece el procesador hay que utilizar modelos de programación paralela. Los modelos clásicos pueden adaptarse a este procesador, como por ejemplo el modelo de memoria compartida. Los SPE pueden procesar los datos en memoria compartida mientras que el PPE les facilita los servicios propios del sistema operativo, como acceso a la memoria, a sistemas de entrada/salida, etc.

Además del modelo de memoria compartida hay otros, como establecer una cola de trabajos de forma que se va repartiendo trabajo a los SPEs según van solicitándolo al unirse a dicha cola. Esta cola la gestiona el PPE y va asignando datos a procesar y espacio en memoria en la que dejar los resultados a los SPEs que estén bloqueados en la cola. Otra posibilidad es formar un pipeline con los SPEs, de manera que van realizando parte del trabajo y pasando el resultado al siguiente SPE que lo continuará, al estilo de una cadena de montaje.
Teniendo memoria compartida, esta puede utilizarse para implementar los métodos habituales de comunicación entre procesos como mutexes, semáforos o paso de mensajes y aprovecharlos para ejecutar varios hilos en paralelo en distintos SPEs.
Otra forma de gestionar los recursos del procesador es mediante el propio sistema operativo, en lugar de hacerlo el desarrollador de la aplicación. Esto se puede realizar de 2 maneras. La primera consiste en considerar los SPEs como un recurso al que se puede acceder representándolo mediante un sistema de ficheros. La segunda estrategia consiste en que el sistema operativo sea capaz de diferenciar entre hilos que deben ejecutarse en el PPE e hilos para los SPEs. En este caso es el kernel del sistema operativo el que se encarga de planificar los hilos y enviarlos a ejecutar a la unidad que corresponda del procesador. El programador puede crear y destruir hilos o tareas para los SPEs mediante llamadas al sistema. Este modelo es el que utiliza el kernel de Linux.

Patxi Astiz
















.png)
